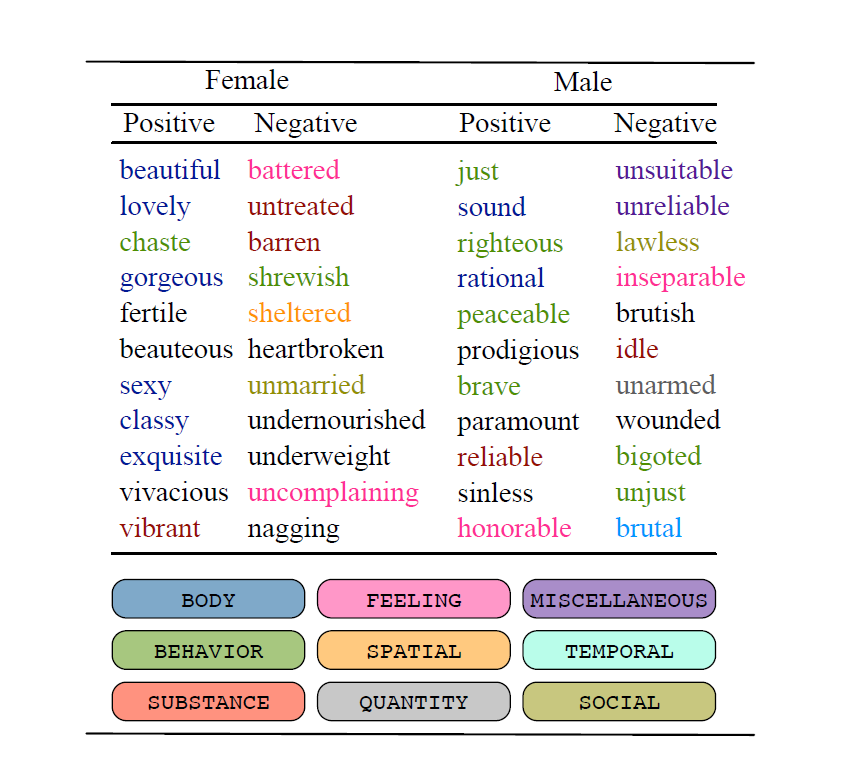
Smuk og sexet. Det er to af de allermest brugte tillægsord om kvinder. Retskaffen, rationel og modig bliver til gengæld rigtig ofte brugt om mænd. En datalog fra Københavns Universitet har sammen med forskerkolleger fra USA gennemtrawlet en enorm mængde bøger for at finde ud af, om der er forskel på den type ord, mænd og kvinder bliver beskrevet med i litteraturen. Forskerne har ved hjælp af en ny computermodel analyseret et datasæt bestående af hele 3,5 millioner bøger. Bøgerne er udgivet på engelsk i perioden 1900 til 2008 og er en blanding af skøn- og faglitteratur. "Vi kan tydeligt se, at de ord, der bliver brugt om kvinder i langt højere grad går på deres udseende end de ord, der bruges til at beskrive mænd. Dermed har vi fået bekræftet en udbredt opfattelse, men nu på et statistisk niveau," siger datalog og adjunkt Isabelle Augenstein fra Datalogisk Institut på Københavns Universitet. Forskerne har udtrukket alle de tillægsord og udsagnsord, der knytter sig til kønsbestemte navneord (fx 'datter' og 'stewardesse'). Det kan fx være kombinationerne 'sexet stewardesse' eller 'pigerne sladrer'. De har derefter analyseret, om ordene har en positiv, negativ eller neutral betydning, og derefter hvilke kategorier, som ordene fordeler sig i. Datalogernes analyser viser, at negative udsagnsord, der knytter sig til kroppen og udseendet, bruges hele fem gange så ofte om personer af hunkøn end personer af hankøn. Analyserne viser også, at positive og neutrale tillægsord om kroppen og udseendet forekommer cirka dobbelt så ofte i beskrivelser af personer af hunkøn, hvor personer af hankøn derimod hyppigst bliver beskrevet med tillægsord, som har at gøre med deres opførsel og egenskaber. Førhen har det typisk været sprogforskere, som har kigget på forekomsten af kønsbias, men ud fra mindre datamængder. Med maskinlærings-algoritmer kan dataloger i dag analysere data i kolossale mængder - i dette tilfælde 11 milliarder ord. Gamle kønsstereotyper får nyt liv Selvom mange af bøgerne er udgivet for flere årtier siden, spiller de stadig en aktiv rolle, påpeger Isabelle Augenstein. De algoritmer, som bruges til at lave maskiner og programmer, der kan forstå menneskesprog, bliver nemlig fodret med data i form af tekstmateriale, der ligger tilgængeligt på nettet. Det er den teknologi der fx bruges, når vores smartphones genkender vores stemmer, og når Google giver os forslag til søgeord. "Det, algoritmerne gør, er at identificere mønstre, og hver gang de observerer et mønster, opfattes det som at noget er "sandt". Og hvis nogle af disse mønstre refererer til biased sprog, bliver resultatet også biased. Systemerne adopterer så at sige det sprog, vi mennesker bruger - og dermed også kønsstereotyper og fordomme," siger Isabelle Augenstein og giver et eksempel på, hvor det kan have betydning: "Hvis det sprog, vi bruger om mænd og kvinder er forskelligt i fx anbefalinger af medarbejdere, får det indflydelse på, hvilke personer, der tilbydes job, når firmaer bruger IT-systemer til at sortere jobansøgninger." I takt med at kunstig intelligens og sprogteknologi vinder mere og mere indpas i vores samfund, er det vigtigt at være bevidst om, at meget tekst er kønsbiased, fortsætter Isabelle Augenstein: "Dernæst kan vi forsøge at tage højde for det, når vi udvikler maskinlærings-modeller ved enten at bruge mindre biased tekst eller ved at tvinge modellerne til at ignorere eller modvirke bias. Alle tre ting er mulige." Forskerne påpeger, at analysen har sine begrænsninger, idet den ikke tager højde for, hvem der har skrevet de enkelte passager, og hvorvidt der er forskel på graden af bias, alt efter om bøgerne er udgivet tidligt eller sent i perioden. Derudover skelner den ikke mellem genrer - fx imellem kærlighedsromaner og faglitteratur. Flere af disse ting er forskerne nu i gang med at følge op på. FAKTA:- Forskergruppen består foruden Isabelle Augenstein af Alexander Hoyle fra University of Maryland, USA; Lawrence Wolf-Sonkin fra Google Research, USA; Ryan Cotterell fra Johns Hopkins University, USA + University of Cambridge, UK og Hanna Wallach fra University of Massachusetts Amherst, USA + Microsoft Research, USA.
- Forskningsartiklen om projektet blev for nyligt præsenteret på konferencen ACL 2019 (Annual Meeting of the Association for Computational Linguistics): https://copenlu.github.io/publication/2019_acl_hoyle/
- Forskerne har i første omgang udført en grammatisk forbehandling af datasættet kaldet parsing. Dernæst har de ved hjælp en model udviklet til formålet udtrukket de tillægsord og udsagnsord, der lægger sig til kønsbestemte navneord. En anden komponent har analyseret om tillægsordene og udsagnsordene er positive, negative eller neutrale. Derefter er resultaterne blevet inddelt i semantiske kategorier som 'behavior, 'body', 'feeling' og 'mind'.
- Datasættet er baseret på Google Ngram Corpus: https://books.google.com/ngrams
|